List
⭐️ArrayList 和 Array(数组)的区别?
ArrayList 内部基于动态数组实现,比 Array(静态数组) 使用起来更加灵活:
ArrayList会根据实际存储的元素动态地扩容或缩容,而Array被创建之后就不能改变它的长度了。ArrayList允许你使用泛型来确保类型安全,Array则不可以。ArrayList中只能存储对象。对于基本类型数据,需要使用其对应的包装类(如 Integer、Double 等)。Array可以直接存储基本类型数据,也可以存储对象。ArrayList支持插入、删除、遍历等常见操作,并且提供了丰富的 API 操作方法,比如add()、remove()等。Array只是一个固定长度的数组,只能按照下标访问其中的元素,不具备动态添加、删除元素的能力。ArrayList创建时不需要指定大小,而Array创建时必须指定大小。
下面是二者使用的简单对比:
Array:
// 初始化一个 String 类型的数组
String[] stringArr = new String[]{"hello", "world", "!"};
// 修改数组元素的值
stringArr[0] = "goodbye";
System.out.println(Arrays.toString(stringArr));// [goodbye, world, !]
// 删除数组中的元素,需要手动移动后面的元素
for (int i = 0; i < stringArr.length - 1; i++) {
stringArr[i] = stringArr[i + 1];
}
stringArr[stringArr.length - 1] = null;
System.out.println(Arrays.toString(stringArr));// [world, !, null]ArrayList :
// 初始化一个 String 类型的 ArrayList
ArrayList<String> stringList = new ArrayList<>(Arrays.asList("hello", "world", "!"));
// 添加元素到 ArrayList 中
stringList.add("goodbye");
System.out.println(stringList);// [hello, world, !, goodbye]
// 修改 ArrayList 中的元素
stringList.set(0, "hi");
System.out.println(stringList);// [hi, world, !, goodbye]
// 删除 ArrayList 中的元素
stringList.remove(0);
System.out.println(stringList); // [world, !, goodbye]ArrayList 和 Vector 的区别?(了解即可)
ArrayList是List的主要实现类,底层使用Object[]存储,适用于频繁的查找工作,线程不安全 。Vector是List的古老实现类,底层使用Object[]存储,线程安全。
Vector 和 Stack 的区别?(了解即可)
Vector和Stack两者都是线程安全的,都是使用synchronized关键字进行同步处理。Stack继承自Vector,是一个后进先出的栈,而Vector是一个列表。
随着 Java 并发编程的发展,Vector 和 Stack 已经被淘汰,推荐使用并发集合类(例如 ConcurrentHashMap、CopyOnWriteArrayList 等)或者手动实现线程安全的方法来提供安全的多线程操作支持。
ArrayList 可以添加 null 值吗?
ArrayList 中可以存储任何类型的对象,包括 null 值。不过,不建议向ArrayList 中添加 null 值, null 值无意义,会让代码难以维护比如忘记做判空处理就会导致空指针异常。
示例代码:
ArrayList<String> listOfStrings = new ArrayList<>();
listOfStrings.add(null);
listOfStrings.add("java");
System.out.println(listOfStrings);输出:
[null, java]⭐️ArrayList 插入和删除元素的时间复杂度?
对于插入:
- 头部插入:由于需要将所有元素都依次向后移动一个位置,因此时间复杂度是 O(n)。
- 尾部插入:当
ArrayList的容量未达到极限时,往列表末尾插入元素的时间复杂度是 O(1),因为它只需要在数组末尾添加一个元素即可;当容量已达到极限并且需要扩容时,则需要执行一次 O(n) 的操作将原数组复制到新的更大的数组中,然后再执行 O(1) 的操作添加元素。 - 指定位置插入:需要将目标位置之后的所有元素都向后移动一个位置,然后再把新元素放入指定位置。这个过程需要移动平均 n/2 个元素,因此时间复杂度为 O(n)。
对于删除:
- 头部删除:由于需要将所有元素依次向前移动一个位置,因此时间复杂度是 O(n)。
- 尾部删除:当删除的元素位于列表末尾时,时间复杂度为 O(1)。
- 指定位置删除:需要将目标元素之后的所有元素向前移动一个位置以填补被删除的空白位置,因此需要移动平均 n/2 个元素,时间复杂度为 O(n)。
这里简单列举一个例子:
// ArrayList的底层数组大小为10,此时存储了7个元素
+---+---+---+---+---+---+---+---+---+---+
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | | | |
+---+---+---+---+---+---+---+---+---+---+
0 1 2 3 4 5 6 7 8 9
// 在索引为1的位置插入一个元素8,该元素后面的所有元素都要向右移动一位
+---+---+---+---+---+---+---+---+---+---+
| 1 | 8 | 2 | 3 | 4 | 5 | 6 | 7 | | |
+---+---+---+---+---+---+---+---+---+---+
0 1 2 3 4 5 6 7 8 9
// 删除索引为1的位置的元素,该元素后面的所有元素都要向左移动一位
+---+---+---+---+---+---+---+---+---+---+
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | | | |
+---+---+---+---+---+---+---+---+---+---+
0 1 2 3 4 5 6 7 8 9⭐️LinkedList 插入和删除元素的时间复杂度?
- 头部插入/删除:只需要修改头结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
- 尾部插入/删除:只需要修改尾结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
- 指定位置插入/删除:需要先移动到指定位置,再修改指定节点的指针完成插入/删除,不过由于有头尾指针,可以从较近的指针出发,因此需要遍历平均 n/4 个元素,时间复杂度为 O(n)。
这里简单列举一个例子:假如我们要删除节点 9 的话,需要先遍历链表找到该节点。然后,再执行相应节点指针指向的更改,具体的源码可以参考:LinkedList 源码分析 。
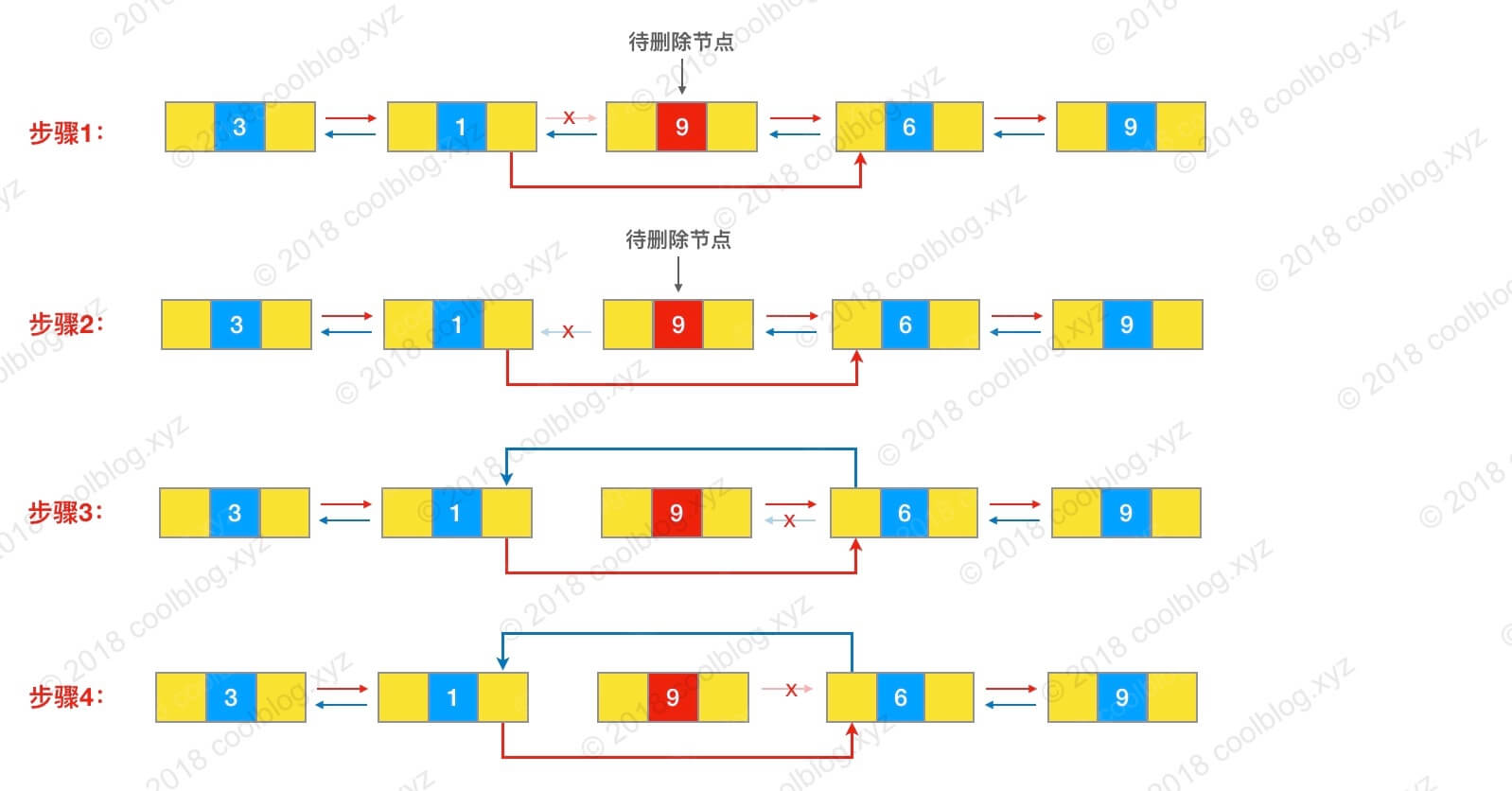
LinkedList 为什么不能实现 RandomAccess 接口?
RandomAccess 是一个标记接口,用来表明实现该接口的类支持随机访问(即可以通过索引快速访问元素)。由于 LinkedList 底层数据结构是链表,内存地址不连续,只能通过指针来定位,不支持随机快速访问,所以不能实现 RandomAccess 接口。
⭐️ArrayList 与 LinkedList 区别?
- 是否保证线程安全:
ArrayList和LinkedList都是不同步的,也就是不保证线程安全; - 底层数据结构:
ArrayList底层使用的是Object数组;LinkedList底层使用的是 双向链表 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!) - 插入和删除是否受元素位置的影响:
ArrayList采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候,ArrayList会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element)),时间复杂度就为 O(n)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。LinkedList采用链表存储,所以在头尾插入或者删除元素不受元素位置的影响(add(E e)、addFirst(E e)、addLast(E e)、removeFirst()、removeLast()),时间复杂度为 O(1),如果是要在指定位置i插入和删除元素的话(add(int index, E element),remove(Object o),remove(int index)), 时间复杂度为 O(n) ,因为需要先移动到指定位置再插入和删除。
- 是否支持快速随机访问:
LinkedList不支持高效的随机元素访问,而ArrayList(实现了RandomAccess接口) 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。 - 内存空间占用:
ArrayList的空间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
我们在项目中一般是不会使用到 LinkedList 的,需要用到 LinkedList 的场景几乎都可以使用 ArrayList 来代替,并且,性能通常会更好!就连 LinkedList 的作者约书亚 · 布洛克(Josh Bloch)自己都说从来不会使用 LinkedList 。
另外,不要下意识地认为 LinkedList 作为链表就最适合元素增删的场景。我在上面也说了,LinkedList 仅仅在头尾插入或者删除元素的时候时间复杂度近似 O(1),其他情况增删元素的平均时间复杂度都是 O(n) 。
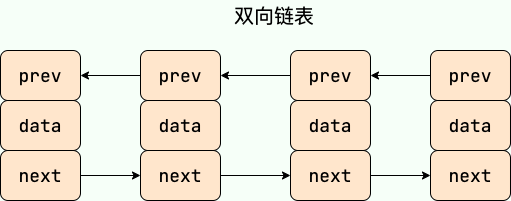
补充内容: 双向链表和双向循环链表
双向链表: 包含两个指针,一个 prev 指向前一个节点,一个 next 指向后一个节点。
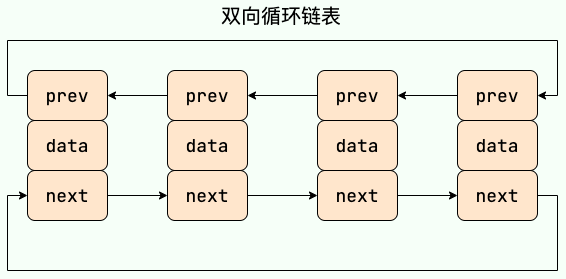
双向循环链表: 最后一个节点的 next 指向 head,而 head 的 prev 指向最后一个节点,构成一个环。
补充内容 接口
public interface RandomAccess {
}查看源码我们发现实际上 RandomAccess 接口中什么都没有定义。所以,在我看来 RandomAccess 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
在 binarySearch() 方法中,它要判断传入的 list 是否 RandomAccess 的实例,如果是,调用indexedBinarySearch()方法,如果不是,那么调用iteratorBinarySearch()方法
public static <T>
int binarySearch(List<? extends Comparable<? super T>> list, T key) {
if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
return Collections.indexedBinarySearch(list, key);
else
return Collections.iteratorBinarySearch(list, key);
}ArrayList 实现了 RandomAccess 接口, 而 LinkedList 没有实现。为什么呢?我觉得还是和底层数据结构有关!ArrayList 底层是数组,而 LinkedList 底层是链表。数组天然支持随机访问,时间复杂度为 O(1),所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n),所以不支持快速随机访问。ArrayList 实现了 RandomAccess 接口,就表明了他具有快速随机访问功能。 RandomAccess 接口只是标识,并不是说 ArrayList 实现 RandomAccess 接口才具有快速随机访问功能的!
⭐️说一说 ArrayList 的扩容机制吧
详见笔主的这篇文章: ArrayList 扩容机制分析。
⭐️集合中的 fail-fast 和 fail-safe 是什么?
fail-fast(快速失败)和 fail-safe(安全失败)是Java集合框架在处理并发修改问题时,两种截然不同的设计哲学和容错策略。
关于fail-fast引用medium中一篇文章关于fail-fast和fail-safe的说法:
Fail-fast systems are designed to immediately stop functioning upon encountering an unexpected condition. This immediate failure helps to catch errors early, making debugging more straightforward.
快速失败的思想即针对可能发生的异常进行提前表明故障并停止运行,通过尽早的发现和停止错误,降低故障系统级联的风险。
在java.util包下的大部分集合(如 ArrayList, HashMap)是不支持线程安全的,为了能够提前发现并发操作导致线程安全风险,提出通过维护一个modCount记录修改的次数,迭代期间通过比对预期修改次数expectedModCount和modCount是否一致来判断是否存在并发操作,从而实现快速失败,由此保证在避免在异常时执行非必要的复杂代码。
ArrayList (fail-fast) 示例:
// 使用线程不安全的 ArrayList,它是一种 fail-fast 集合
List<Integer> list = new ArrayList<>();
CountDownLatch latch = new CountDownLatch(2);
for (int i = 0; i < 5; i++) {
list.add(i);
}
System.out.println("Initial list: " + list);
Thread t1 = new Thread(() -> {
try {
for (Integer i : list) {
System.out.println("Iterator Thread (t1) sees: " + i);
Thread.sleep(100);
}
} catch (ConcurrentModificationException e) {
System.err.println("!!! Iterator Thread (t1) caught ConcurrentModificationException as expected.");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
latch.countDown();
}
});
Thread t2 = new Thread(() -> {
try {
Thread.sleep(50);
System.out.println("-> Modifier Thread (t2) is removing element 1...");
list.remove(Integer.valueOf(1));
System.out.println("-> Modifier Thread (t2) finished removal.");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
latch.countDown();
}
});
t1.start();
t2.start();
latch.await();
System.out.println("Final list state: " + list);输出:
Initial list: [0, 1, 2, 3, 4]
Iterator Thread (t1) sees: 0
-> Modifier Thread (t2) is removing element 1...
-> Modifier Thread (t2) finished removal.
!!! Iterator Thread (t1) caught ConcurrentModificationException as expected.
Final list state: [0, 2, 3, 4]程序在线程 t2 修改列表后,线程 t1 的下一次迭代操作立刻就抛出了 ConcurrentModificationException。这是因为 ArrayList 的迭代器在每次 next() 调用时,都会检查 modCount 是否被改变。一旦发现集合在迭代器不知情的情况下被修改,它会立即“快速失败”,以防止在不一致的数据上继续操作导致不可预期的后果。
对此我们也给出for循环底层迭代器获取下一个元素时的next方法,可以看到其内部的checkForComodification具有针对修改次数比对的逻辑:
public E next() {
//检查是否存在并发修改
checkForComodification();
//......
//返回下一个元素
return (E) elementData[lastRet = i];
}
final void checkForComodification() {
//当前循环遍历次数和预期修改次数不一致时,就会抛出ConcurrentModificationException
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
而fail-safe也就是安全失败的含义,它旨在即使面对意外情况也能恢复并继续运行,这使得它特别适用于不确定或者不稳定的环境:
Fail-safe systems take a different approach, aiming to recover and continue even in the face of unexpected conditions. This makes them particularly suited for uncertain or volatile environments.
该思想常运用于并发容器,最经典的实现就是CopyOnWriteArrayList的实现,通过写时复制(Copy-On-Write)的思想保证在进行修改操作时复制出一份快照,基于这份快照完成添加或者删除操作后,将CopyOnWriteArrayList底层的数组引用指向这个新的数组空间,由此避免迭代时被并发修改所干扰所导致并发操作安全问题,当然这种做法也存在缺点,即进行遍历操作时无法获得实时结果:
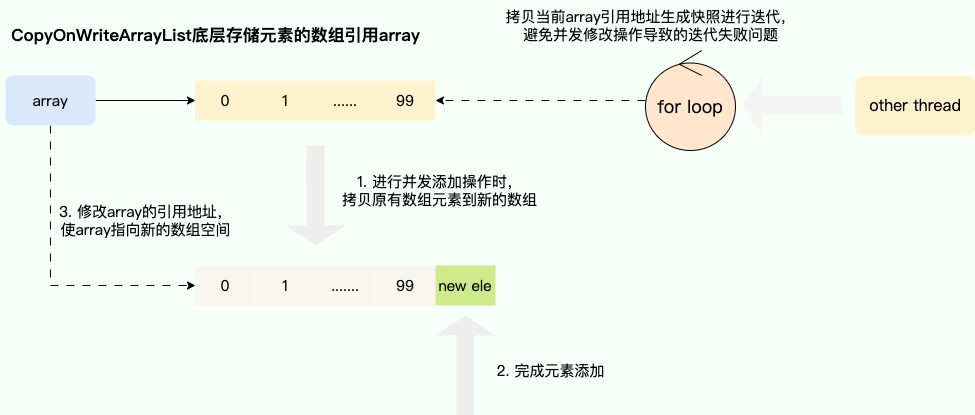
对应我们也给出CopyOnWriteArrayList实现fail-safe的核心代码,可以看到它的实现就是通过getArray获取数组引用然后通过Arrays.copyOf得到一个数组的快照,基于这个快照完成添加操作后,修改底层array变量指向的引用地址由此完成写时复制:
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
//获取原有数组
Object[] elements = getArray();
int len = elements.length;
//基于原有数组复制出一份内存快照
Object[] newElements = Arrays.copyOf(elements, len + 1);
//进行添加操作
newElements[len] = e;
//array指向新的数组
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
评论
使用 GitHub 账号即可参与加载较慢?可 直接前往 GitHub Discussions 查看与参与。